

This is a short video of my recent presentation at AI Tinkerers Seattle meetup.
The demo shows 6 different models running in parallel to execute the exact same task. This setup is useful to compare models for creating task specific vertical agents. I recently compared a different set of models to create a specialized agent just for testing. This section of my previous post covers the comparison in detail.
Key Findings
After 8+ tasks across 6 models (3 local, 3 cloud):
• No single model won everything. Claude dominated code changes. GPT-4.1 won simpler tasks. Local models won when complexity was low.
• Token usage varied 52x between models on the same task with no correlation to quality. More tokens ≠ better output.
• All 3 local models (ollama) scored 0/10 on code modifications but 9-10/10 on simpler tasks. Privacy and cost benefits are real, but only for the right task types.
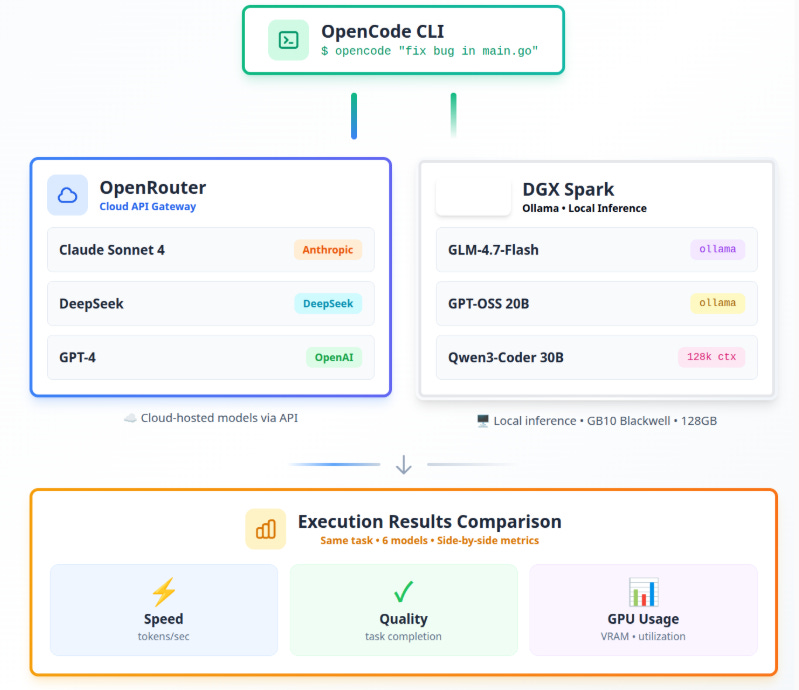
Workflow
This is the high level workflow this project follows for each task. OpenCode CLI or the browser provides the task which is processed in parallel. Once all LLMs complete this task, the judge decides the best output and merges it to the target application
Takeaways
Why experiments like this are important for any org planning to build agents.
Use the best LLM(or SLM) for the task. Subsidized pricing (yes, I’m talking about all those free Opus 4.6 tokens) makes it easier to use the largest model for checking time of the day but they will pull the plug on this
Cost. Smaller, specialized models are getting better with each release
Privacy. For enterprises or security sensitive orgs, using local models may be a better fit
For accuracy, model selection per task is a key decision to enforce the right guardrails and get high quality output
Full leaderboard and experiment setup in the video.If you’re experimenting with multi-model setups or building task-specific vertical agents, would love to compare notes. DM me.
