
Migrating from Claude Code to OpenCode
Engineers need model flexibility and customization for best results. Closed ecosystems block them from doing this.

I’ll set some context(pun intended) before I start this post. I’m doing this for a few reasons
Coding tool discussions (similar to language or editor discussions) tend to escalate fast. The context helps clarify that my suggestions here are a part of my journey and in no way a recommendation for anyone.
I’ve learned a lot from similar writeups by more experienced devs. If this can help someone get better at their work, I’d have done a small bit to give back to the community
I’ve written code for almost a decade and half and shipped products in various languages and frameworks. I’m a big believer of is famous quote by Abraham Lincoln
Give me six hours to chop down a tree and I will spend the first four sharpening the axe.

With this guiding principle I’ve spent countless hours in making my dev setup “perfect”. For almost everyone else, this setup is complex, clunky or simply overkill but this works for me in ways I need it to. More specifically, it is a combination of following
Xubuntu 24.04 LTS
Wezterm (migrated to this from Terminator in 2025)
Tmux with session management (15+ permanent sessions and then some ephemeral ones)
Tmux restore session (to auto restore sessions on reboot)
Guake to just drop a terminal for a quick command or two when i dont want to Alt+Tab
(Neo)Vim for all and every change that needs text input
Mix of usual plugins (Tree, Telescope, Tab, etc) with a few unusual ones
Give me a shout out if you’ve made Avante.nvim work with AWS Bedrock
As of 2025, Claude Code
For work Claude Code is setup with AWS Bedrock
For personal projects I use Claude Code Max subscription, gemini-cli, Codex, and Openrouter (for all other models),
As you might’ve guessed by now, I live in the terminal and always have. It was after I got my hands on Claude Code I realized the main reason my AI usage for dev tasks was pretty low: I couldn’t get myself to use the IDEs which is how most coding agents launched (Yes, I know VSCode has VIM keybindings but lets not go there).
With this out of the way, lets move on to the more interesting part of the post.
Claude Code days
Claude Code was addictive from day 1. Especially for engineers who spend a lot of time CLI, this came as a superpower. You had an assistant who just “gets” you. Gone are the days of remembering commands flags, mistyping commands (who remember sl ?) or going spending hours in RTFM.

Over time, I expanded my flow to include non-coding tasks as well. The tmux session list I talked about earlier, started growing with multiple sessions running Claude Code for specific tasks. This included
Daily executive summaries (hook up Atlassian MCP and gh cli)
Sprint analysis, management and planning
Finding blockers in sprint, over allocation, under allocation, work distribution etc etc
Responding to comments
Architecture reviews (Pull architecture docs from Confluence, code from GH, requirements from JIRA, go to work)
Researching topics, understanding API contracts, CLI’s and SDKs
Building personal dashboards for anything and everything
Creating agents, plugins, marketplaces to distribute common patterns with my team
Creating more agents to help me do more stuff that I don’t want to
And yes, coding
I probably forgot a few things here but you get the drift. Every tech meetup or event I went to, I learnt of more interesting stuff others were doing and tried to add some of it in my workflow.
This worked until Claude Code’s goals were aligned with mine: Get more done in the best way possible.
Turns out, other providers offered solutions but Claude Code wasn’t helping me try out those solutions.
Claude Code - The Dark Side
I guess I got carried away with the title there. Anyway, the reality is that Claude Code(and the likes) is a for profit product and will try to always lock the user to its ecosystem. All those (nearly) free tokens for a pricey model like Opus 4.5 don’t come without any strings attached. Every engineer I met in last 6 months agrees that Anthropic models are best at writing code but a non-trivial number of those engineers are also using other models for non-coding tasks. Codex and Gemini are the other two alternatives being used for planning or reviewing a plan or ideation or code generated by Sonnet/Opus.
Claude Code (and Codex, Gemini-CLI and Cursor) make it harder to leave by either simply being better than competition or by providing addon features. Claude Code has especially done a great job at this by first introducing MCPs about a year and half ago, then adding subagents, Skills, Marketplace and higher usage limits. I used all these features heavily to add layers on my workflows and by stringing multiple workflows together. I get more work done, Claude gets more token usage. Both win.
My mental model for AI agent usage is to explore both the application layer(usability features) and the foundational layer(LLM specific capabilities).
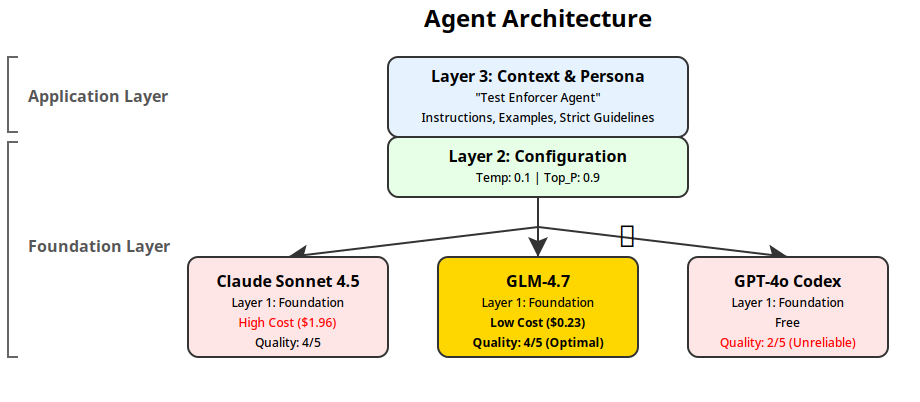
As much as Claude Code was doing a good job at the application layer, I didn’t get any control over the foundational layer. Simple example: I created a test-enforcer subagent in Claude Code with a lot of context and examples. But I couldn’t tweak the LLM parameters like Temperature, Top p or other values for this agent. I want this test enforcer agent to not have any creativity (which is opposite of what I want from a researcher agent). If these values are configurable at the LLM layer (Claude Agent SDK allows you to change it), then why should this not be available for Claude Code users to configure?
As my coding and non-coding workflow moved from treating the agent as a single assistant to multiple assistants with specific personas, I started getting frustrated with the inability to customize my agents beyond context engineering. Just this functionality can help users build very tight, reusable agents using the same foundation model.
Another pain point was the inability to switch models to find the best model for the agent. I kept hearing about new model launches which performed better(or at least claimed to) than other in certain aspects. Be it reasoning, tool execution, tool selection or other criteria in SWE Bench.
The goal was(is) to find the best model(brain) for the agent(persona).
For this, I needed to experiment fast. Yes, I can create a custom tool with all the Agent SDK’s and run eval to figure this out, which I did. But I need to know how it performs on my live setup, not some eval. This will become more clear when I explain later what I’m doing now.
Enter OpenCode
I tracked OpenCode development since its first launch. In the spirit of making my system perfect, I evaluate every tool before settling down on one. I rejected OpenCode a few months ago for multiple reasons which they’ve fixed since.
It was one of my teammates who made the switch from Claude Code to OpenCode that made me go back to it. After a few hours of playing around with it, I was ready for the switch. Over last week, I migrated all my agents, skills, configurations and MCPs to OpenCode and it’s working great.
I’ll first talk about what I’m loving so far and then dive into a concrete example.
Agent configuration
Right off the bat, my agent configurations are now fine tuned to what the agent is expected to do. Here’s an example of DevOps expert agent.
---
description: Expert guidance on DevOps practices, infrastructure as code, CI/CD pipelines, and microservices deployment.
mode: all
tools:
read: true
write: true
edit: true
bash: true
permission:
edit: allow
bash: allow
temperature: 0.1
top_p: 0.9
[more LLM specific configurations as needed]
---
[Agent instructions follow...]The mode: all setting means this agent can be invoked both as a primary agent and as a subagent (automatically called by other agents). In Claude Code, you choose one or the other. Not both.
This limitation forced me to duplicate my architect agent. I needed one version configured as a slash command for direct design reviews, and another configured as a subagent so it would be automatically invoked during code reviews. Maintaining two copies of the same agent with identical instructions was brittle and error-prone.
When I’d run “review these changes with all agents,” my architect agent wouldn’t participate because it was configured as a slash command, not a subagent. The choice was binary: direct invocation OR automatic invocation. OpenCode’s mode: all solves this cleanly
Model Flexibility
My workflow relies on three core agents, each optimized with a different model:
Architect Agent uses Opus 4.5. Its job is to find inconsistencies, suggest better architectural patterns, and evaluate trade-offs. This requires high reasoning capability and creativity.
Test Agent uses Sonnet 4. Its job is zero creativity: follow existing test patterns and increase coverage. For this I need a model that is cost-effective and fast for repetitive, structured work like generating tests that mirror existing examples.
API-Spec Updater Agent uses Sonnet 4. Its job is to enforce that API specs stay current with code changes and flag any unapproved modifications. Again, zero creativity needed, just pattern enforcement.
Using the right model for each agent isn’t about preference. It’s about reliability. When the test agent has access to creative reasoning, it sometimes introduces novel test patterns that don’t match the existing codebase style. When the architect agent is constrained by a pattern-following model, it misses architectural nuances. Model choice directly affects agent trustworthiness.
Claude Code locks you to Claude models. There’s no way to use GLM, z-ai, Qwen, MiniMax, or any other specialized model provider’s model per agent. You can swap models globally, but that defeats the purpose of specialized agents. Yes, I’ve used zen MCP for this but I found the integration to be slow and unpredictable.
Case Study: Test Enforcer Agent
To take my new setup for a spin, I set out to build the best Test Enforcer agent for my requirements. Here are the steps
Clearly define the test enforcer agent persona, objectives, response format and specialization in agent definition.
also add LLM parameters.
temperature=0.1, top_p=0.9
Make some changes in a branch using my regular dev process
This is a mix of Sonnet and Opus
Spin up 5 OpenCode instances(tmux) on this branch
Switch to “Test Enforcer Agent” for each instance
This means all 5 instances use exactly the same agent configuration
These 5 instances are using: Sonnet 4.5, Gemini 3.0 Pro, DeepSeek v3.2, GLM-4.7, GPT-4o Codex
Give all 5 instances the exact same prompt
“Review test cases for this branch”
Brew my coffee
Here are the results
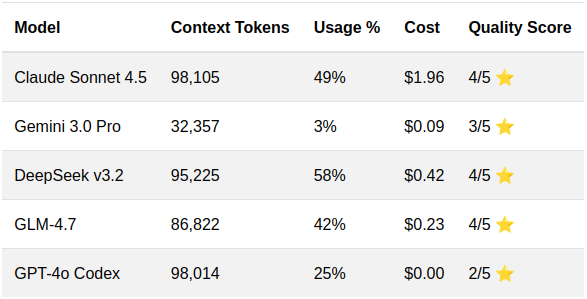
The results reveal why model selection per agent is critical. Here’s a truncated feedback from all the providers:
Claude Sonnet 4.5 provided the most detailed analysis with excellent layer-by-layer breakdown:
Coverage Analysis (Detailed)
- Overall Coverage: 88.5% ✅ Exceeds 80% threshold
Breakdown by Layer:
- Handler Layer: 86.9% - Excellent
- admin_oem_handler.go: CreateOEM (85.7%), ListOEMs (77.8%),
GetOEM (100%), DeleteOEM (100%)
- oem_handler.go: Login (85.7%), GetOwnProfile (100%),
UpdateOwnProfile (77.8%)
- Gap: getOEMIDFromContext (71.4%) - missing some error path tests
- Service Layer: 74.4% - Good (closest to threshold)
- Strong: ListOEMs (100%), comparePassword (100%), mapToDTO (100%)
- Needs Attention: GetOwnProfile (37.5%), DeleteOEM (66.7%),
UpdateOwnProfile (69.2%), Login (73.9%)
- Critical Gap: GetOwnProfile only 37.5% covered
Gemini 3.0 Pro was cost-effective but provided basic analysis:
Review Summary
Rating: 3/5 ⭐⭐⭐
Overall coverage is 88.6% (✅ Meets 80% target), but the Service Layer
is lagging at 74.4%.
| Layer | Coverage | Status |
| :--- | :--- | :--- |
| Validator | 100.0% | ✅ Excellent |
| Repository | 93.2% | ✅ Excellent |
| Handler | 86.9% | ✅ Good |
| Service | 74.4% | ⚠️ Below Threshold |
Critical Gaps (Must Fix)
1. Service Layer: Missing error handling for hashPassword failure
2. Service Layer: Missing error handling for database failures
3. Service Layer: Missing error handling for token generation failure
DeepSeek v3.2 balanced cost and thoroughness:
Rating: 4/5 ⭐
Summary
Excellent test coverage with comprehensive scenarios for the new
management feature. Tests follow repository patterns, have good mocking,
and cover most error conditions. Minor improvements needed in API
response code validation and edge case coverage.
Test Pattern Analysis
- Follows repo conventions: ✅ Yes
- Table-driven tests: ✅ Present
- Mock usage: ✅ Appropriate (gomock for service/repository interfaces)
- Test isolation: ✅ Isolated
- HTTP testing: ✅ Present (httptest with Fiber framework)
GLM-4.7 delivered strong analysis at competitive pricing:
Rating: 4/5 ⭐
Summary
Good test coverage with solid fundamentals. The management feature
has comprehensive tests across all layers (handler, service, repository,
validator) with 100% validator coverage and strong repository coverage
(93.2%). Most happy paths and error scenarios are covered. However,
authentication middleware tests, concurrency safety, and some edge
cases are missing.
Coverage Analysis
- Current: 86.9% (handler), 93.2% (repository), 74.4% (service),
100.0% (validator)
- Target: 80.0%
- Status: ✅ Meets threshold
Test Pattern Analysis
- Follows repo conventions: ✅ Yes
- Table-driven tests (Go): ✅ Present (in validator tests)
- Mock usage: ✅ Appropriate (gomock with proper controller management)
- Test isolation: ✅ Isolated (proper setup/teardown with defer ctrl.Finish())
GPT-4o Codex was free(almost) but delivered subpar analysis:
Rating: 2/5 ⭐
Summary
Core OEM handlers, repository, and validator tests are well-structured
and follow repo conventions, but service-level error paths are
under-tested and the overall module coverage is far below the 80% target.
Coverage Analysis
- Current: 58.6%
- Target: 80.0%
- Status: ⚠️ Below threshold (-21.4%)
Test Pattern Analysis
- Follows repo conventions: ✅ Yes
- Table-driven tests (Go): ✅ Present (validator coverage)
- Mock usage: ✅ Appropriate (gomock + sqlmock)
- Test isolation: ✅ Isolated
The model comparison reveals distinct value propositions. GLM-4.7 emerges as the optimal choice for this test enforcement agent: 88% cheaper than Sonnet with identical 4/5 quality rating, more efficient token usage (42% vs 58%), and accurate coverage analysis with specific improvement recommendations like authentication middleware testing and concurrency safety.
DeepSeek v3.2 remains competitive at $0.42, but GLM-4.7’s superior cost efficiency ($0.23) and comparable analysis depth make it the clear winner for repetitive test review workflows. Sonnet’s premium pricing becomes harder to justify when specialized models deliver equivalent results at a fraction of the cost.
GPT-4o Codex, despite being free, significantly underperformed with incorrect coverage calculations (58.6% vs the actual 88.5%) and a lower quality rating. This demonstrates that cost isn’t the only consideration—accuracy and reliability matter more for automated workflows where incorrect analysis could mislead development decisions.
This is why OpenCode’s per-agent model selection matters. I can optimize each agent for its specific task characteristics, cost requirements, and quality thresholds.
OpenCode’s Approach
OpenCode is provider-agnostic. I configure access to both AWS Bedrock (for Claude models) and OpenRouter (for GLM-4, MiniMax, DeepSeek, and others) in a single interface. Each agent specifies which model it uses in its configuration.
The agent configuration is straightforward markdown frontmatter:
mode: all/primary/subagentcontrols invocation patternstools: {}grants granular access to specific capabilitiespermission: {}sets fine-grained edit and bash permissions
Beyond agent flexibility, OpenCode fixed several workflow issues that were impacting my productivity with Claude Code:
Flicker problem resolved. Claude Code’s UI would flicker when editing large files (specs, long documentation). This happened frequently as my workflow shifted toward spec-first development. OpenCode doesn’t have this issue.
Better scrolling behavior. In Claude Code, I had to use tmux shortcuts to scroll through long responses. But that meant that the input box would disappear when scrolling up. OpenCode lets me use simple page-up/page-down while keeping the input visible, making it easier to provide feedback on lengthy code reviews.
Image paste support. Claude Code on Wayland had persistent issues with image pasting(X11 works fine). OpenCode handles this correctly out of the box.
LSP support out of the box. Language Server Protocol integration works automatically for Go, JavaScript, and Python files. This means better autocompletion and inline errors during agent-assisted coding.
Session sharing. I can generate a shareable link to any conversation and send it to teammates. This is useful for debugging agent configurations or showing examples of effective prompts.
Editor mode. Instead of typing prompts in a command box, I can use vim to craft detailed multi-paragraph instructions with proper formatting. This significantly improves how I communicate complex requirements to agents. Especially when writing initial plans for complex tasks, this provides a distraction free way to just dump all thoughts on a blank slate (sadly, this is one of the few ways I still get to use vim)
Trade-offs
This doesn’t come for free so please venture into this territory if you’re sure.
Learning curve. OpenCode has more keyboard shortcuts to remember. It’s similar to moving from an IDE to vim. There’s an adjustment period to become productive. I’m still learning the keybinds.
Missing visual features. Claude Code’s “ultrathink” visual indicator shows when the model is reasoning deeply. The status bar provides useful context about what the agent is doing. The marketplace makes discovering new integrations easy. OpenCode lacks these polish elements.
Manual mode switching. OpenCode has separate plan and execute modes that I switch between manually using the Tab key. Claude Code handles this transition seamlessly when it automatically moves from planning to execution without user intervention. This adds friction to my workflow.
MCP configuration complexity. Model Context Protocol servers require more manual setup in OpenCode compared to Claude Code’s streamlined approach. I have more control, but it takes more effort to configure initially.
These aren’t dealbreakers for my workflow, but they’re real costs. If you value visual polish and seamless UX over configurability, Claude Code may be the better choice.
When This Matters
Not everyone needs multi-agent workflows with per-agent model selection. If you’re using a single AI assistant for coding tasks, Claude Code’s simplicity and polish are advantages.
The signal that you need OpenCode’s flexibility: you’re building more than 2-3 specialized agents and hitting limits on how you can configure them. Specifically:
You need agents to be both directly callable and auto-invoked by other agents
You need different agents using different models based on task characteristics (like using DeepSeek for test reviews and Sonnet for architecture decisions)
You’re iterating on agent behavior and need fast configuration changes
You need to use specialized models (GLM-4.7 for cost-efficient pattern-following, DeepSeek v3.2 for balanced performance) alongside general-purpose models
For me, model flexibility and agent invocation control outweigh visual polish. My agents deliver more reliable results and are trustworthy when I can match the right model to each task. GLM-4.7 handles test enforcement at $0.23 with the same quality as Sonnet’s $1.96, while my architect agent still benefits from Sonnet’s deep reasoning capabilities. OpenCode makes this optimization possible. Once I’ve selected the model, I will customize it further using its model specific settings (for GLM-4.7, https://huggingface.co/zai-org/GLM-4.7 ).
Key Takeaways
Agent specialization requires model flexibility. Different tasks need different LLM characteristics. Pattern-following work (tests, spec enforcement) benefits from models optimized for batch operations. Architecture decisions benefit from models optimized for reasoning. One-size-fits-all model selection limits agent effectiveness. My test enforcer comparison showed DeepSeek v3.2 delivering 79% cost savings over Sonnet with comparable quality for structured tasks.
Cost optimization through model selection. Per-agent model choice isn’t just about capabilities, it’s about cost efficiency and accuracy. The test enforcer comparison revealed GLM-4.7 as the optimal choice: 88% cheaper than Sonnet with identical 4/5 quality rating and more efficient token usage. Running every agent on premium models wastes budget on tasks that specialized models can handle better and cheaper, while free models like GPT-4o Codex can produce unreliable results that mislead development decisions.
Invocation patterns matter. Agents should be callable both directly (slash commands) and by other agents (subagents) without duplication. The mode: all configuration in OpenCode solves this cleanly.
Tool lock-in has real costs. Provider coupling limits your ability to optimize agent effectiveness. As new specialized models are released (like GLM-4 for coding tasks), being provider-agnostic lets you adopt them immediately. With agentic coding now being the de-facto way to write code, engineers are working on higher complexity tasks on their machines. They need access to the best tools to get reliable outcomes.
Visual polish vs. configurability is a real trade-off. Claude Code’s seamless UX and visual indicators are valuable. OpenCode’s flexibility comes with more manual configuration. Choose based on whether you prioritize ease of use or control.
If you’re hitting agent customization limits or need model flexibility per agent, evaluate OpenCode. I’d love to hear how others are architecting their agent teams. Reach out at hello@devashish.me if you’re navigating similar challenges.
thank you for making us understand 'whats the difference in opencode - under the hood version' details.
Great detail on the tradeoffs as well as the comparison between models! I’m yet to try OpenCode (still working on getting the best out of Claude Code) but this is a great read